Note
Go to the end to download the full example code. or to run this example in your browser via Binder
One-way functional ANOVA with real data#
This example shows how to perform a functional one-way ANOVA test using a real dataset.
# Author: David García Fernández
# License: MIT
# sphinx_gallery_thumbnail_number = 4
One-way ANOVA (analysis of variance) is a test that can be used to compare the means of different samples of data. Let \(X_{ij}(t), j=1, \dots, n_i\) be trajectories corresponding to \(k\) independent samples \((i=1,\dots,k)\) and let \(E(X_i(t)) = m_i(t)\). Thus, the null hypothesis in the statistical test is:
To illustrate this functionality we are going to explore the data available in GAIT dataset from fda R library. This dataset compiles a set of angles of hips and knees from 39 different boys in a 20 point movement cycle.
from skfda.datasets import fetch_gait
from skfda.representation.basis import FourierBasis
dataset = fetch_gait()
fd_hip = dataset["data"].coordinates[0]
fd_knee = dataset["data"].coordinates[1].to_basis(FourierBasis(n_basis=10))
Let’s start with the first feature, the angle of the hip. The sample consists in 39 different trajectories, each representing the movement of the hip of each of the boys studied.
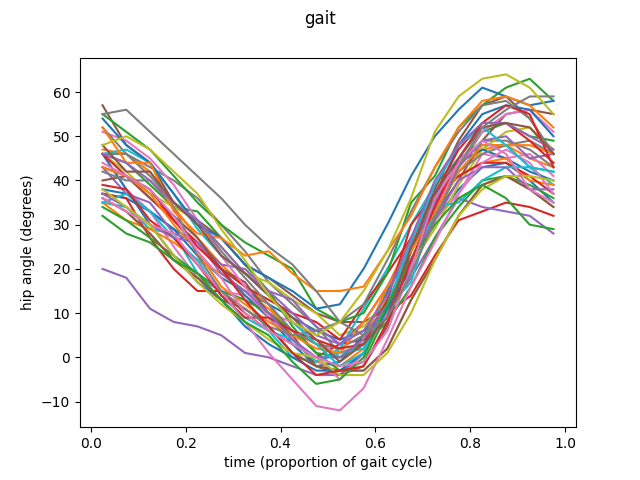
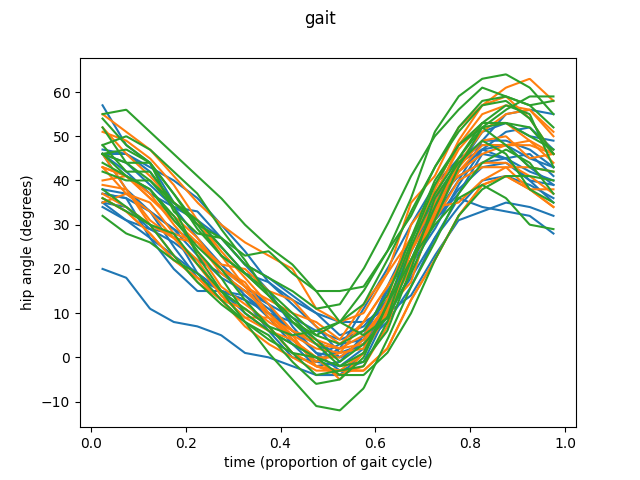
The example is going to be divided in three different groups. Then we are going to apply the ANOVA procedure to this groups to test if the means of this three groups are equal or not.
import skfda
partition_size = len(fd_hip) // 3
fd_hip1 = fd_hip[:partition_size]
fd_hip2 = fd_hip[partition_size:2*partition_size]
fd_hip3 = fd_hip[2*partition_size:]
group = [0] * partition_size + [1] * partition_size + [2] * partition_size
fd_hip.plot(group=group)
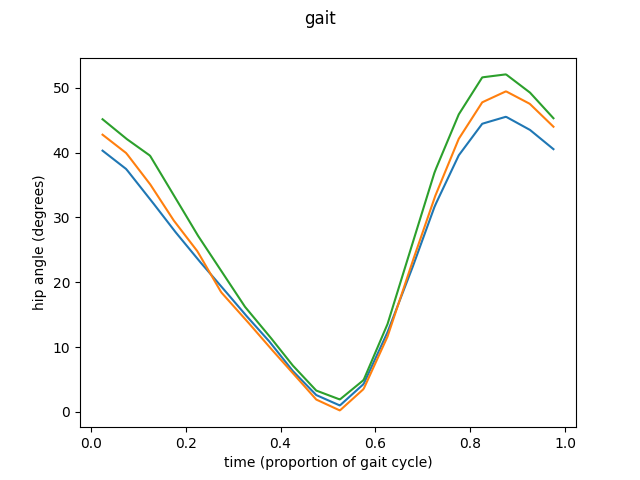
means = [fd_hip1.mean(), fd_hip2.mean(), fd_hip3.mean()]
fd_means = skfda.concatenate(means)
fig = fd_means.plot()
At this point is time to perform the ANOVA test. This functionality is
implemented in the function oneway_anova(). As
it consists in an asymptotic method it is possible to set the number of
simulations necessary to approximate the result of the statistic. It is
possible to set the \(p\) of the \(L_p\) norm used in the
calculations (defaults 2).
from skfda.inference.anova import oneway_anova
v_n, p_val = oneway_anova(fd_hip1, fd_hip2, fd_hip3)
The function returns first the statistic v_sample_stat() used to measure the variability between groups,
second the p-value of the test . For further information visit
oneway_anova() and
Cuevas et al.[1].
Statistic: 368.0564102564103
p-value: 0.211
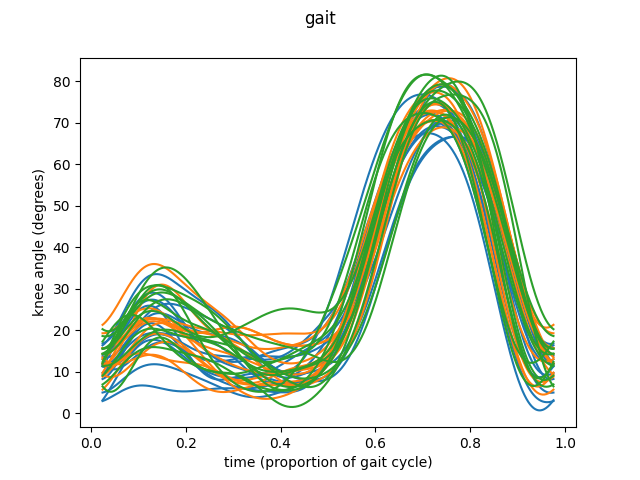
This was the simplest way to call this function. Let’s see another example, this time using knee angles, this time with data in basis representation.
fig = fd_knee.plot()
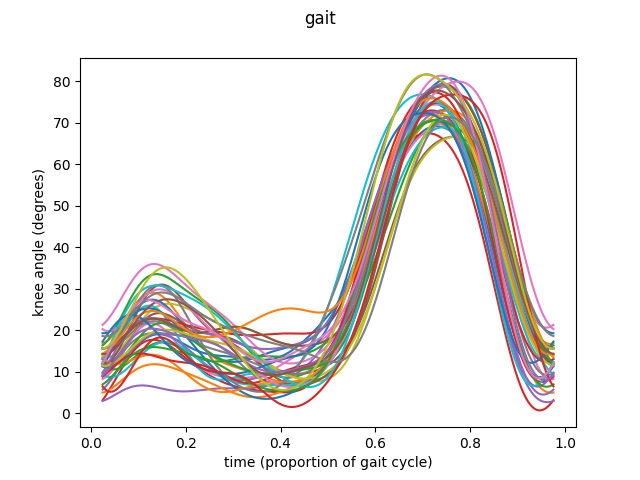
The same procedure as before is followed to prepare the data.
fd_knee1 = fd_knee[:partition_size]
fd_knee2 = fd_knee[partition_size:2*partition_size]
fd_knee3 = fd_knee[2*partition_size:]
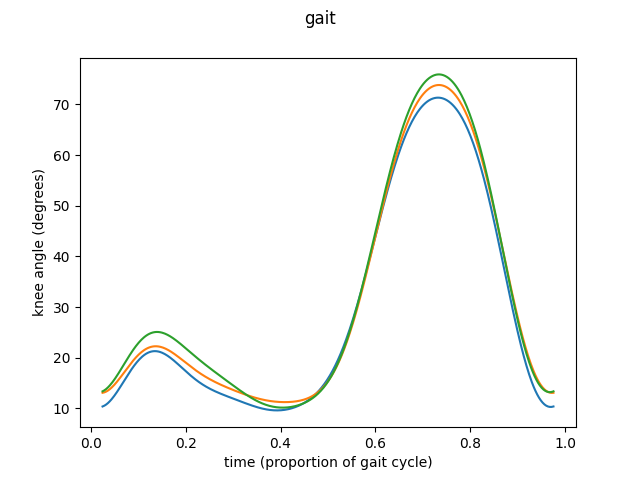
fd_knee.plot(group=group)
means = [fd_knee1.mean(), fd_knee2.mean(), fd_knee3.mean()]
fd_means = skfda.concatenate(means)
fig = fd_means.plot()
In this case the optional arguments of the function are going to be set.
First, there is a n_reps parameter, which allows the user to select the
number of simulations to perform in the asymptotic procedure of the test (
see oneway_anova()), defaults to 2000.
Also there is a p parameter to choose the \(p\) of the \(L_p\) norm used in the calculations (defaults 2).
Finally we can set to True the flag dist which allows the function to return a third value. This third return value corresponds to the sampling distribution of the statistic which is compared with the first return to get the p-value.
Statistic: 178.58753775850403
p-value: 0.5373333333333333
Distribution: [142.34277489 414.10429495 206.35728306 ... 165.20062804 413.9226641
70.94140327]
- References:
Total running time of the script: (0 minutes 0.656 seconds)